ElasticSearch简介
ElasticSearch是一个基于Lucene的开源的文本搜索引擎。Lucene是一个基于Java的全文信息检索工具包,功能强大,性能好,广泛用于检索的相关应用中。不过要使用Lucene需要对检索的相关知识有所了解,而且要使用Java集成到自己的应用中,开发成本相对很高。ElasticSearch基于Lucene实现了所有的索引和搜索的功能,通过简单的REST API隐藏Lucene内部的复杂性,让全文检索的应用变得更加简单通用。ElasticSearch支持分布式实时的文件存储,索引和分析,通过扩展可以支持PB级的结构化或者非结构化的数据。
基本概念
ElasticSearch的基本概念涉及Node,Cluster,Index,Document,Type等,这里就不一一列举和解释了,官方的文档已经解释得足够详细。不过这里有一张图把这些概念总结了一下,放在一起看会很清晰:
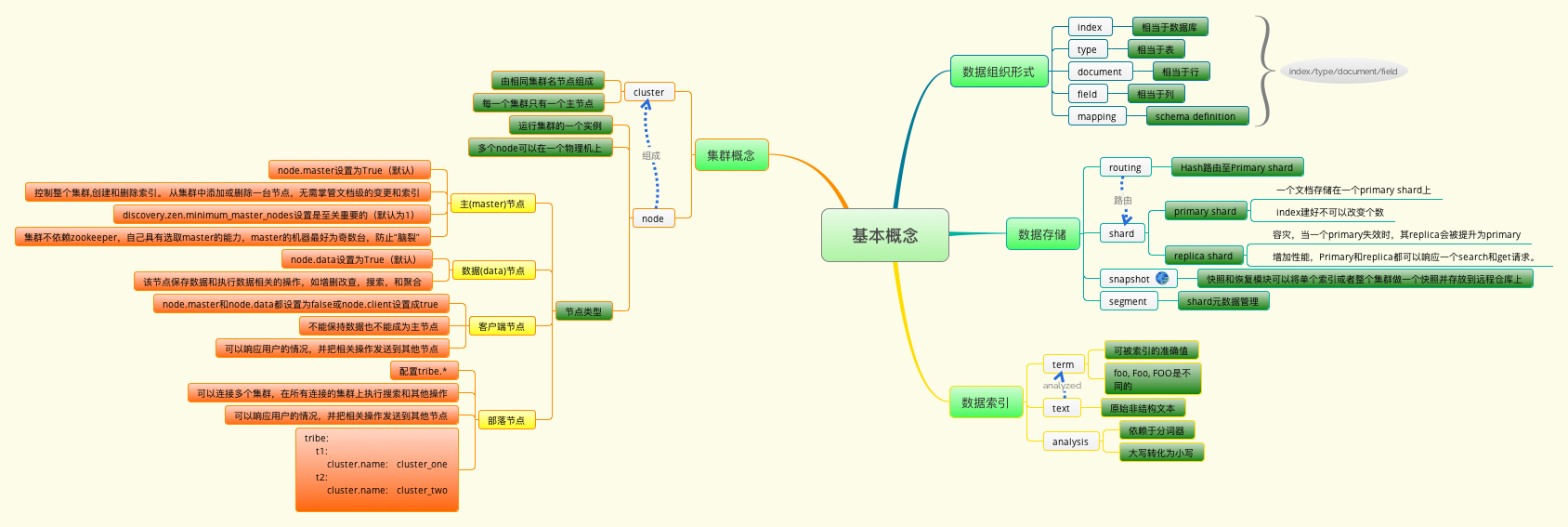
ElasticSearch架构图
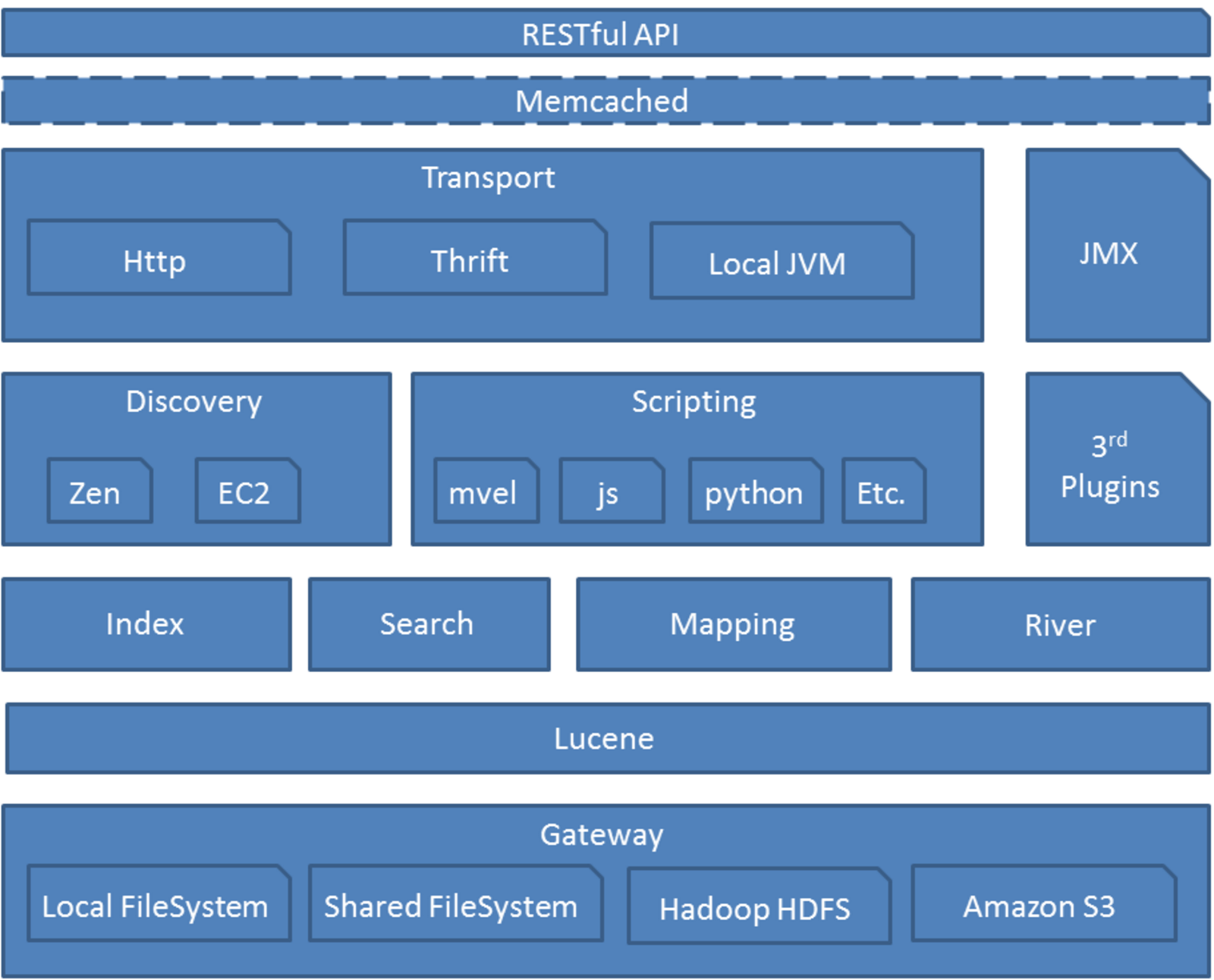
ElasticSearch采用Guice作为依赖注入框架,网络使用Netty, 提供HTTP REST和RPC两种协议接口。Elasticsearch 之所以用guice,而不是用spring做依赖注入,关键的一个原因是Guice可以帮它很容易的实现模块化,通过代码进行模块组装,可以很精确的控制依赖注入的管理范围。比如 Elasticsearch 给每个shard单独生成一个injector,可以将该shard相关的配置以及组件注入进去,降低编码和状态管理的复杂度,同时删除shard的时候也方便回收相关对象。
请求流程
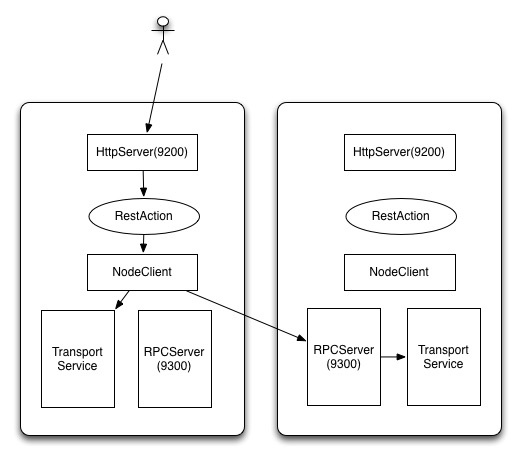
上面是简化之后的REST请求流程图:
- 用户发起http请求, 传给对应的RestAction;
- RestAction将REST请求转化为RPC的TransportRequest, 然后调用NodeClient,相当于是客户端的方式调用RPC;
这样做的好处是实现了http和RPC的两层隔离,增加了部署的灵活性。部署的时候既可以同时开启RPC和http服务,也可以用client模式部署一组服务专门提供HTTP REST服务,另外一组只开启RPC服务,专门做data节点,便于分担压力。
ElasticSearch 的RPC的序列化机制使用了 Lucene 的压缩数据类型,支持vint这样的变长数字类型,省略了字段名,用流式方式按顺序写入字段的值。每个需要传输的对象都需要实现如下两个方法:
void writeTo(StreamOutput out)
T readFrom(StreamInput in)
虽然这样实现开发成本略高,增删字段也不太灵活,但对 ElasticSearch 这样的数据库系统来说,不用考虑跨语言,增删字段肯定要考虑兼容性,这样做效率最高。所以 ElasticSearch 的RPC接口只有Java Client可以直接请求,其他语言的客户端都走的是REST接口。
网络层
Elasticsearch 的网络层抽象很值得借鉴。它抽象出一个 Transport 层,同时兼有client和server功能,server端接收其他节点的连接,client维持和其他节点的连接,承担了节点之间请求转发的功能。ElasticSearch 为了避免传输流量比较大的操作堵塞连接,所以会按照优先级创建多个连接,称为channel。
- recovery: 2个channel专门用做恢复数据。如果为了避免恢复数据时将带宽占满,还可以设置恢复数据时的网络传输速度。
- bulk: 3个channel用来传输批量请求等基本比较低的请求。
- regular: 6个channel用来传输通用正常的请求,中等级别。
- state: 1个channel保留给集群状态相关的操作,比如集群状态变更的传输,高级别。
- ping: 1个channel专门用来ping,进行故障检测。
每个节点默认都会创建13个到其他节点的连接,并且节点之间是互相连接的,每增加一个节点,该节点会到每个节点创建13个连接,而其他每个节点也会创建13个连回来的连接。
线程池
由于Java不支持绿色线程(fiber/coroutine),线程池里保留多少线程合适?如何避免慢的任务占用线程池,导致其他比较快的任务也得不到执行?很多应用系统里,为了避免这种情况,会随手创建线程池,最后导致系统里充塞了大的量的线程池,浪费资源。而 ElasticSearch 的解决方案是分优先级的线程池。它默认创建了10多个线程池,按照不同的优先级以及不同的操作进行划分。然后提供了4种类型的线程池,不同的线程池使用不同的类型:
-
CACHED 最小为0,无上限,无队列(SynchronousQueue,没有缓冲buffer),有存活时间检测的线程池。通用的,希望能尽可能支撑的任务。
- DIRECT 直接在调用者的线程里执行,其实这不算一种线程池方案,主要是为了代码逻辑上的统一而创造的一种线程类型。
- FIXED 固定大小的线程池,带有缓冲队列。用于计算和IO的耗时波动较小的操作。
- SCALING 有最小值,最大值的伸缩线程池,队列是基于LinkedTransferQueue 改造的实现,和java内置的Executors生成的伸缩线程池的区别是优先增加线程,增加到最大值后才会使用队列,和java内置的线程池规则相反。用于计算和IO耗时都不太稳定,需要限制系统承载最大任务上限的操作。
这种解决方案虽然要求每个用到线程池的地方都需要评估下执行成本以及应该用什么样的线程池,但好处是限制了线程池的泛滥,也缓解了不同类型的任务互相之间的影响。
集群
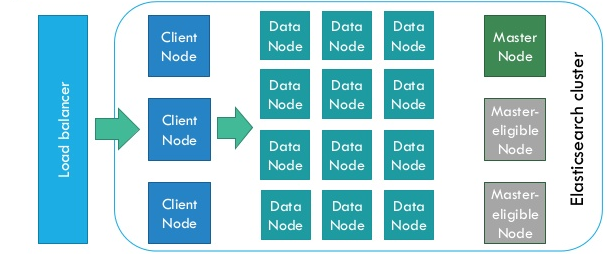
ElasticSearch集群中的节点分为三类:
- Master Node: 只负责集群的管理,不存储数据,也不接受HTTP API请求;
- Client Node:只负责处理HTTP API请求,不存储数据;
- Data Node:只负责存储数据,不接受HTTP API请求;
下图是一个典型的ElasticSearch集群架构图:
集群管理最佳实践
- 最好是给集群和节点一个有意义的名字;
- ES会在节点启动的时候随机给节点指定一个名字,一方面会使得管理变得混乱, 另一方面会使日志变得混乱。
- 不要将数据,日志和插件的路径配置在安装目录下;
- minium_master_nodes对集群的稳定及其重要。
- 这个配置就是告诉ES当没有足够master候选节点的时候,不要进行master选举;一般设置为master候选节点的大多数,(master候选节点个数 / 2) + 1。
- 集群恢复:recover_after_nodes/expected_nodes/recover_after_time, 避免集群在重启的时候过多的分片交换。
- 用单播代替组播,防止节点无意中加入集群。
管理工具
Docker支持
ElasticSearch的设计使得它非常容易支持Docker,下面是对Kubernetes和Swarm的支持:
参考:
https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
https://www.jikexingqiu.com/search?q=elasticsearch
https://github.com/jacksu/awesome-es/blob/master/README.md
https://elk-docker.readthedocs.io/
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-discovery-zen.html
https://www.elastic.co/blog/found-leader-election-in-general
http://docs.splunk.com/Documentation/Splunk/6.6.2/Indexer/Aboutindexesandindexers
https://blog.insightdatascience.com/anatomy-of-an-elasticsearch-cluster-part-i-7ac9a13b05db
https://blog.insightdatascience.com/anatomy-of-an-elasticsearch-cluster-part-ii-6db4e821b571
http://jolestar.com/elasticsearch-architecture/
-End-