Gluten
What is Gluten?
Gluein Latin- Enable Spark with Native Vectorized Execution
- Contributed by Intel and Kyligence in 2022
Photon
SIGMOD 2022: A Fast Query Engine for Lakehouse Systems[1]- Not open source
Why we need it?
- IO bound ==> CPU bound
- JIT is not enough
- Spark 1.4: Expression Compute
- Spark 2.0: Stage Code Generation (Volcano Model)
- Query plan level performance improves, but not operator level
- JVM is not good for CPU instruction optimization (like SIMD)
- Existing native engine like
volex/clickhouse/arrow
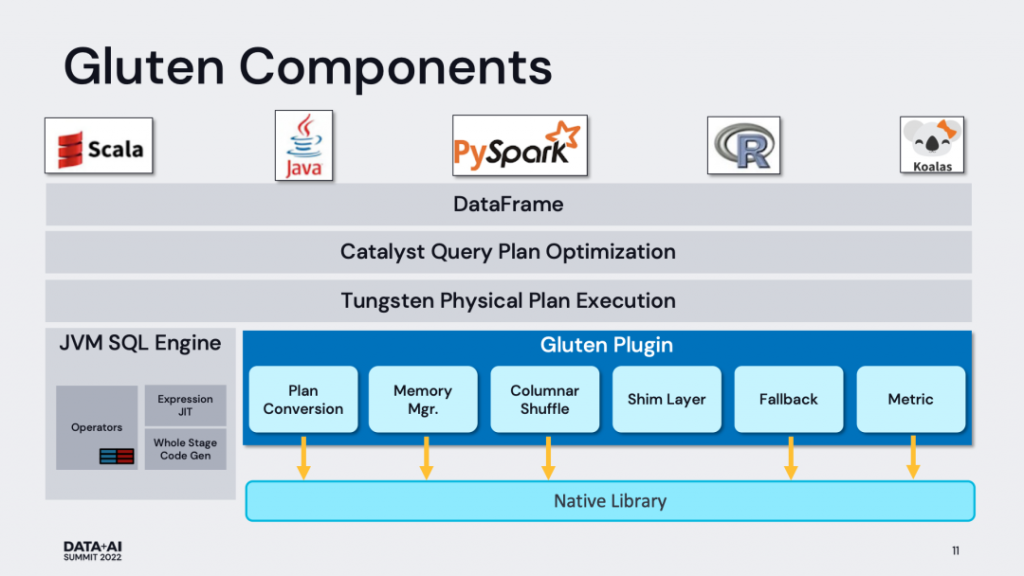
Spark Plugin
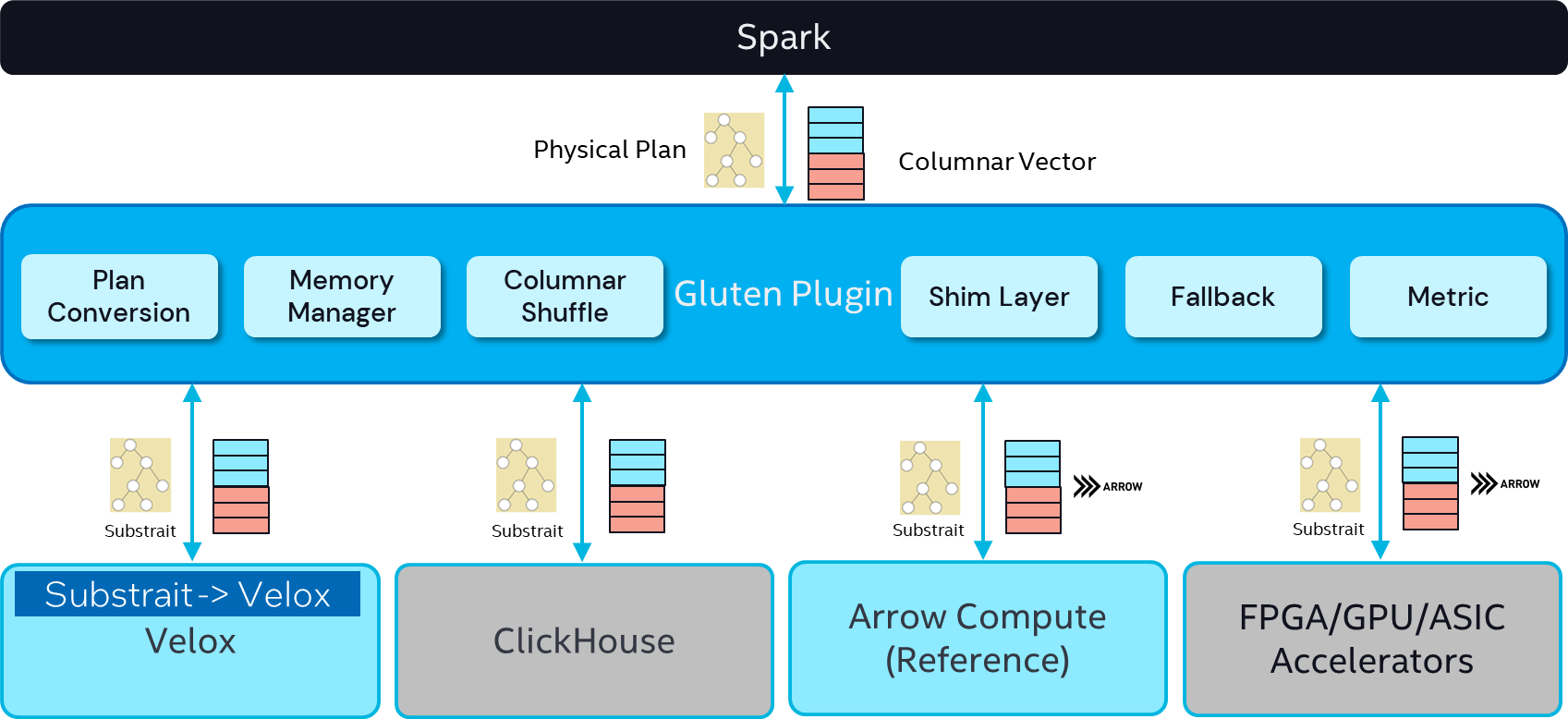
Architecture
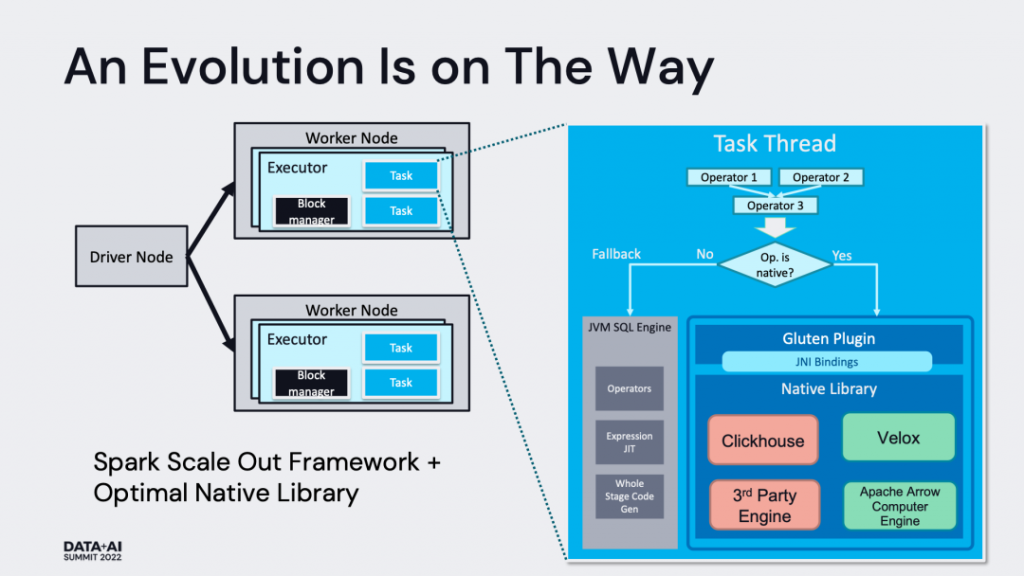
Design Goal
- Transform Spark’s stage physical plan to Substrait plan
- Offload performance-critical data processing to native library
- Define clear JNI interfaces for native libraries
- Switch available native backends easily
- Reuse Spark’s distributed control flow
- Manage data sharing between JVM and native
- Extensible to support more native accelerators
Plan Conversion & Fallback
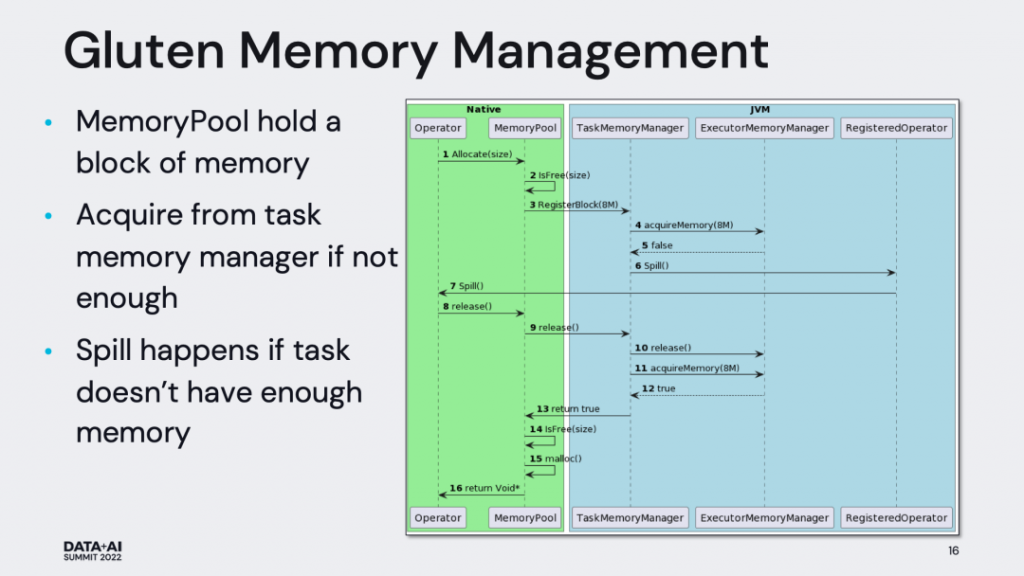
Memory Management
Columnar Shuffle
- Row to column
- On Shuffle Read phase
Compability
- Clear JNI interface
- Spark Side: shim layer
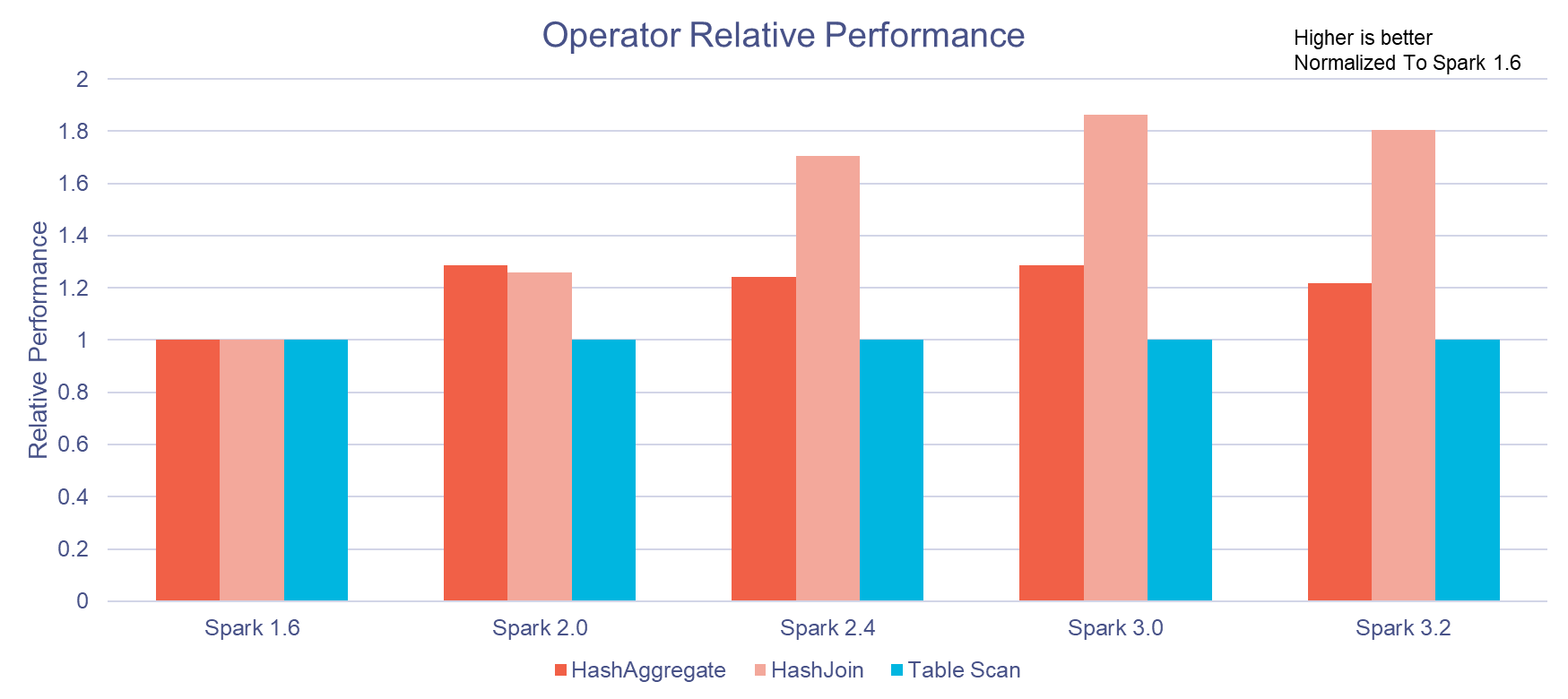
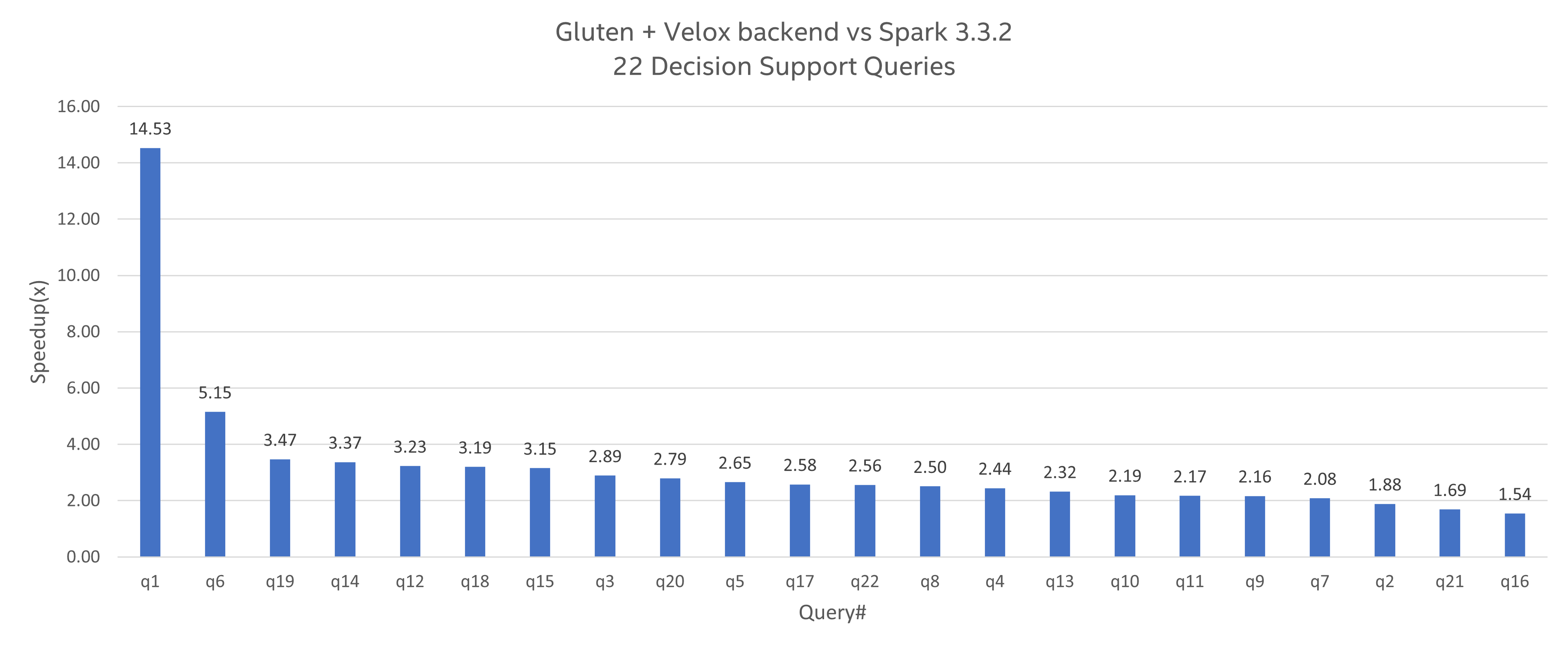
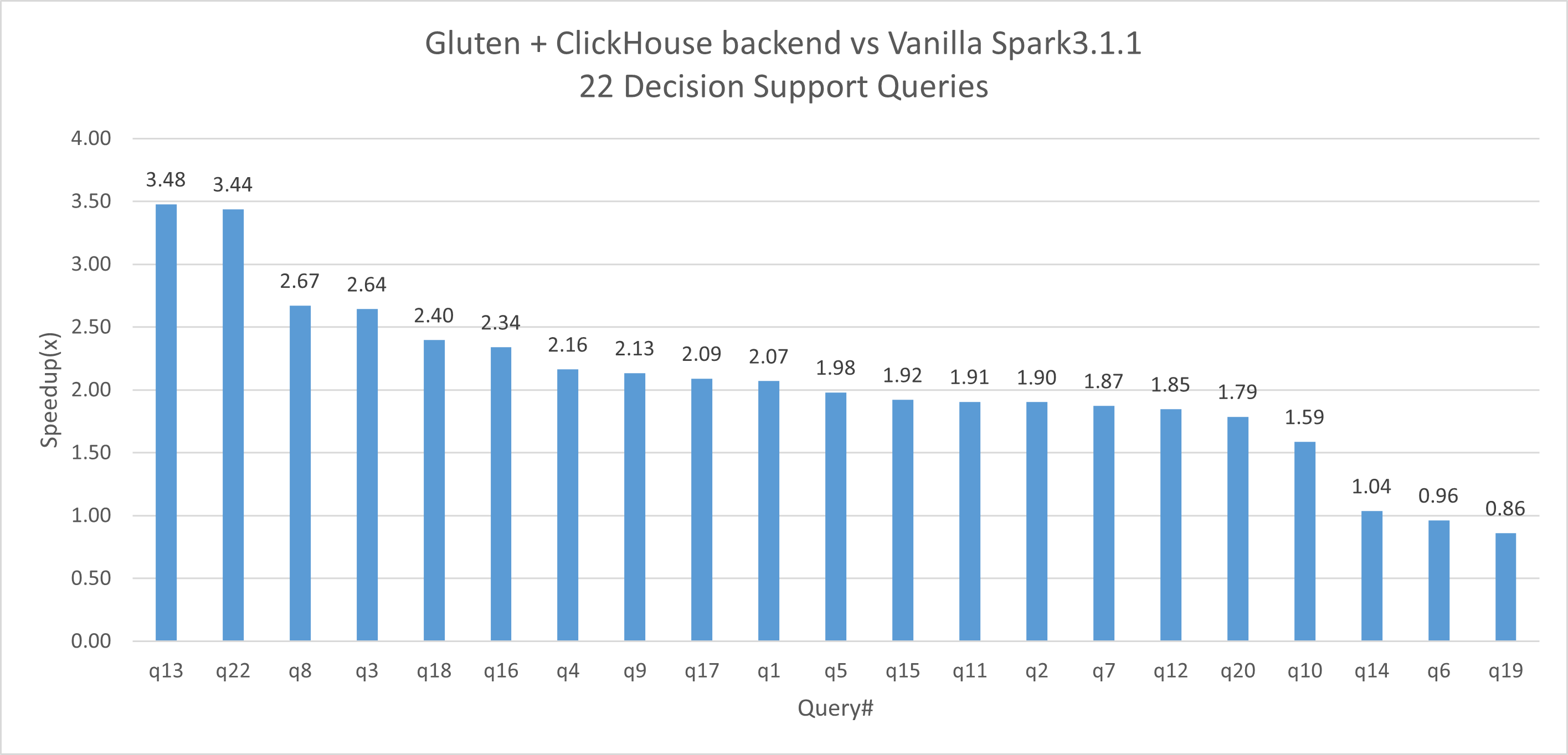
Performance
Who are using it?
References
- https://cs.stanford.edu/people/matei/papers/2022/sigmod_photon.pdf
- https://github.com/oap-project/gluten
- https://cn.kyligence.io/blog/gluten-spark/
- https://github.com/facebookincubator/velox/
- https://medium.com/intel-analytics-software/accelerate-spark-sql-queries-with-gluten-9000b65d1b4e
- https://www.databricks.com/dataaisummit/session/best-exploration-columnar-shuffle-design/